Object Oriented Teens blog
Stay updated with the latest insights, tutorials, and opinions from our team of tech experts.
Stay updated with the latest insights, tutorials, and opinions from our team of tech experts.
Abhishek Madaan
January 18, 2026
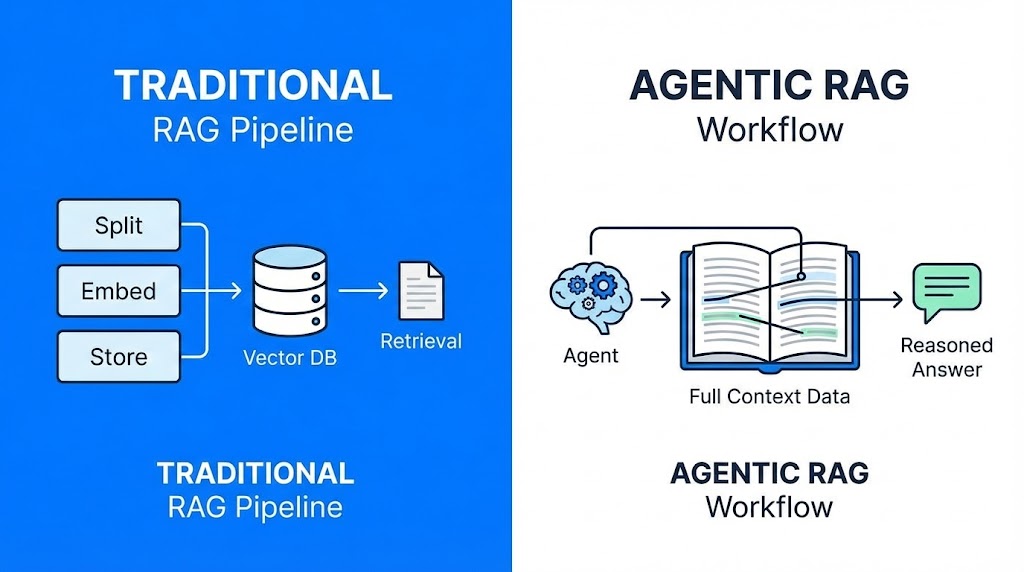
Headlines like “RAG is dead” or “Vector DBs are obsolete” exaggerate the truth, but they reflect a real shift in how Retrieval-Augmented Generation systems are built. Rigid, pre-chunked pipelines are giving way to agentic systems that can read full documents and decide what matters at runtime.
Traditional RAG emerged when LLMs had small context windows:
Problem: This approach breaks long-range context, is brittle, and often leads to hallucinations when answers span multiple sections of a document.
Two advances made this approach less necessary:
Instead of pre-processing everything:
This mirrors how humans search and read: scan, focus, contextualize, then answer.
For many use cases (PDF Q&A, contract analysis, medium codebases):
Traditional RAG isn’t gone—it’s shrinking in scope. At massive scales, retrieval is still needed to narrow data down. But it’s becoming a backend optimization, not the core design.
The future of RAG is agent-driven: systems that can fetch, read, and understand information on their own.